一个很明显的事实是,AI的进步速度依然很快,而且超出了很多人的预期。
文字创作方面,Claude 3.7 Sonnet这样的大模型已经能够应付大多数场景下的写作需求,不仅输出质量稳定,文笔也十分简洁;而在图片生成领域,GPT-4o对宫崎骏画风的“神还原”则更让人印象深刻。事实上,只要在提示词上稍微下点功夫,AI完全可以应对部分内容生成的工作,用于有效提高生产力。
当然,在其他能力方面,AI的进步也同样明显,特别是在编程领域。
先是Gemini 2.5 Pro (I/O edition)以王者之姿登顶编程排行榜,后有云端AI编程智能体Codex半小时完成数天软件工程任务,甚至连GitHub也在最近推出了Copilot AI代理,用来提升开发者的工作效率与代码产出质量。
“人人都是开发者”的时代似乎马上就要到来,但对开发者来说,这显然不是什么好消息。
如何确保自己不被替代,在AI时代不被行业所抛弃,是一个不得不考虑的重要问题。
最直接的办法是“打不过就加入”,大模型潜力固然很强,但一般不会单独发挥作用,反而是和各种应用相结合才能在各种场景中落地,从这个角度来看,学习大模型应用开发是一个提升自我的有效途径。
然而,极高的算力门槛、复杂的技术栈以及缺乏完整的能力提升路径则成为了摆在大多数人面前的致命问题。
正是在这样的背景下,英特尔携手火山引擎团队,围绕基于英特尔至强6性能核的火山引擎第四代计算实例g4il展开了一系列工作,让“一杯奶茶钱启动大模型应用开发”成为了可能。
CPU: AI推理的“瑞士军刀”
本地部署大模型,进行AI应用开发是一个好选择吗?是,也不是。
对企业来说,从数据隐私、响应速度等方面来看,本地部署能够提供更稳定和可靠的计算能力,避免可能存在的网络波动或服务中断等影响,但伴随而来的还有高昂的成本。
而从个人角度出发,更易获得、支持快速部署且计费方式灵活的云服务,无疑是更适合应用开发的选择。
这也让英特尔与火山引擎多年来围绕IaaS进行的深度合作变得更有意义。
作为最基础的资源层,IaaS涵盖了非常广泛的场景和各种各样的虚拟机云实例,包括通用型、本地盘、高主频、突发/共享、网络增强、内存增强、安全增强等等,火山引擎第四代通用型实例g4il正是在这样的背景之下诞生的。
与前三代类似,第四代实例不仅实现了包括数据库应用、Web应用、图像渲染能力在内的通用性能提升,还实现了AI性能的显著增强。

这实际上有些反常识,要知道在过去几年里,很多人都认为CPU更适合通用算力,而不适合AI算力。但严格来说,这个看法并不完全准确,一个完整的AI工程可以划分为数据收集、模型选型、推理、训练、部署维护和迭代优化等各个步骤,每个步骤对算力的要求都有所不同,尽管GPU更擅长处理大量并行任务,在执行计算密集型任务时表现地更出色,但在进行AI推理时,如何比较CPU和GPU的性能差异其实一直缺乏一个明确的答案。
英特尔技术专家表示,从本质上来说,CPU可以理解为一把能够执行多种任务的“瑞士军刀”,特别是英特尔至强处理器在AMX加速器的赋能之下,在矩阵运算能力方面也有了显著提升,特别适合资源有限、推理规模较小的开发验证场景。

除此之外,目前业界普遍采用CPU和GPU混合推理的异构计算方式,具体来说,在开发验证阶段会以低成本易获取的CPU为主,而在生产部署阶段则会使用GPU进行大规模的推理运算,二者各自发挥优势,协同工作,而不是相互替代的关系。
换句话说,CPU在AI时代仍然有很大的舞台,特别是在大模型应用开发方面。
大模型应用开发三要素,缺一不可
当然,大模型开发对普通开发者来说也并非易事,一是大模型领域技术更新极快,RAG、MCP、A2A等新名词层出不穷,让开发者望而却步;二是不知从何入手,缺乏具体的启动策略;三是没有系统性的学习支持,难以实现能力的阶段性提升。
这也就引申出了大模型应用开发的三要素:第一是硬件环境,用于验证和练习;第二是软件栈,需要主流的软件栈支持;第三则是由浅入深的指导课程,不仅能够运行,更要深度理解,真正实现能力的进阶。而英特尔与火山引擎合作的初衷,就是为开发者们打造一把低门槛的梯子,帮助更多人迈出跨越的第一步。

硬件方面,基于英特尔至强6处理器的第四代实例g4il在AMX加速器的赋能下拥有了更强的AI推理性能,据英特尔技术专家透露,基于CPU内置的AI加速器和软硬件协同优化,可以做到在一个云实例中,仅使用16vCPU或32vCPU即可部署和运行7B或14B的大模型,而16vCPU在火山引擎官网的定价仅仅只有3.8元/小时,开发者可以通过极低的成本开启大模型应用开发实践,更关键的是,与市面上常见的4bit量化不同,该方案采用了BF16精度,可以在性能提升的同时最大化保留精度。
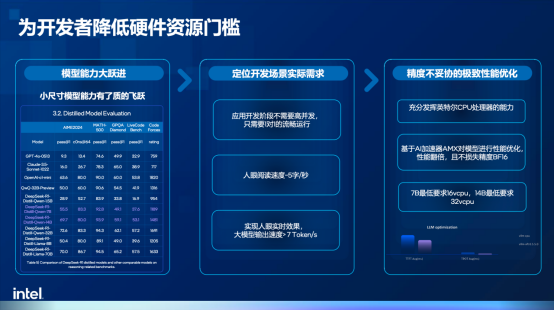
镜像则基于英特尔开源社区OPEA(Open Platform for Enterprise AI)所构建,通过开放架构和组件式模块化的架构,开发者可以通过“搭积木”的方式打造可扩展的AI应用部署基础。此外,由于社区中积累了大量经过预先验证的、优化的开源应用范例,英特尔也将这些范例和软件栈打包成了虚拟机镜像,开发者可以通过一键部署的方式快速搭建硬件和软件环境。
为了能让开发者从核心基础开始循序渐进掌握大模型应用开发的相关知识,英特尔也和火山引擎共同打造了免费的实操课程,内容涵盖基础环境搭建、代码开发环境配置、模型调优、性能优化等各个环节,旨在帮助基础薄弱的开发者补齐知识储备,理解技术原理,并通过实际操作来实现个人能力的提升。

英特尔技术专家表示,通过整套的课程,普通开发者能够更加熟悉、更加了解大模型,也能实现对大模型的“祛魅”。
RAG实践加速大模型应用落地
大模型是万能的吗?显然不是。时至今日,大模型在数学能力的方面依然存疑,这是由大模型本身的架构所决定的,本质上讲,大模型并没有真正的记忆力,也无法主动更新知识库,所有的输出结果都是根据自身的参数来计算,这会导致两个主要问题。
首先是幻觉。大模型的输出内容基于概率,且随着输出内容长度的增加,概率偏差会逐渐累积,可能导致大模型产生幻觉,完全依赖自身记忆参数。这种幻觉在短期内难以消除,除非AI或大模型的计算范式发生颠覆性变化。
其次是大模型无法获取知识更新。由于预训练过程投喂的数据集是固定的,大模型并没有能力预知未来发生的新变化。
正是因为这两个缺陷的存在,当前几乎所有的大模型应用都会强调,大模型的“记忆”需要外部数据源或者数据库进行对接,来构建知识库以更新或补充知识。所有任务和问答内容的上下文都要从知识库中提取,然后由大模型输出,因此,知识库是大模型应用开发中非常重要的核心基础。
此外,大模型效果不稳定的情况也很大程度上取决于数据的准确性,这也就意味着数据的基础决定了应用的下限。而这个数据基础的核心就是RAG(检索增强)技术,这一技术的主要目的就是通过向量数据库检索、网页检索、图数据库检索或关联数据库检索等方式,实现和大模型的对接,但最基本的是向量数据库与大模型的配合。
通常来说,RAG技术包括数据源准备和问答/任务处理两个阶段。在数据源准备过程,企业需要构建知识库,也就是把相关的重要文档加载到向量库中,这一过程主要涉及到文档分段及向量化等操作,其中向量化的目的不只是检索关键词,更重要的是实现语义检索,以保证更广泛的覆盖面。
在问答/任务处理阶段,则需要把问题做Embedding(语义匹配),例如衣服、裤子这些词汇虽然字面上并不相同,但其实语义相关,然后VDB(检索向量数据库)会提取相关的上下文内容,并进行修改、调整和不相关内容的过滤,最后再将问题和相关内容提供给大模型生成回答。
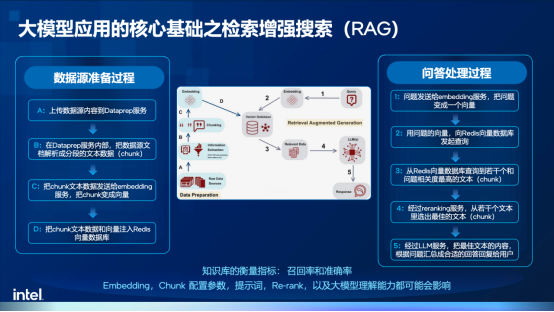
在整个过程中,数据基础有两个关键指标:召回率和准确率。前者代表检索到的内容和问题的全面性和相关性,而后者则代表检索到的内容和问题的相关程度。这两个指标直接决定了大模型应用的体验,因此,Embedding模型的选择、chunk的大小和划分方法等课题,都需要在实践中进行反复优化,才能真正理解技术的精髓,从而为智能体开发打好基础。
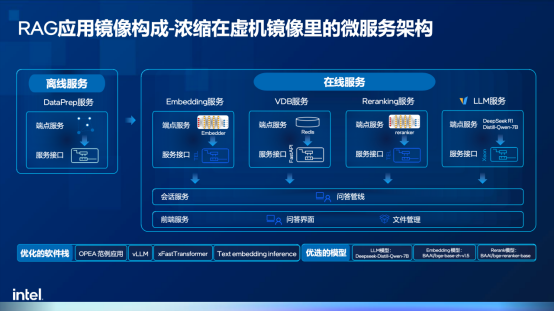
这也是英特尔和火山引擎推出RAG应用镜像的原因之一,该镜像实现了RAG全流程模快的集成,包含Embedding模块、向量数据库、Re-Rank,以及一个7B参数的DeepSeek蒸馏模型,并在文档准备工作中提供了用于在线问答的服务Dataprep。而对开发者来说,通过火山引擎选择云实例后,仅需3分钟左右就能完成环境部署,掌握大模型应用开发的核心思路,为构建精准、合规的智能体应用奠定基础。
结语
步入智能数字化时代,大模型技术正在加速AI应用的大规模应用。而英特尔与火山引擎的合作,正是对AI惠普的进一步实践,通过基于英特尔至强6的g4il实例、软件栈支持和配套课程,英特尔与火山引擎正在为广大开发者们架起一座通向Agentic AI未来的桥梁。

































 京公网安备 11010202008829号
京公网安备 11010202008829号